一个能一键分析批量下载nhentai本子的纯Shell脚本,下完还能自动打包成zip。
主要是给VPS用的,批量快速下完打包然后拉回来一气呵成(。
Head Pic: 「アストルフォきゅん」/「イチリ」
nhentai-one-key-downloader
但由于 shell 脚本仍存在很多问题,不建议使用,有兴趣可以看这个
演示视频
视频约1.7MB
演示内容顺序:
- 模式A 白名单
- 模式B + 断点续传
- 模式A 黑名单 + 查重
准备工作
首先你需要有Linux。。。VPS也可虚拟机也可。
然后用以下命令下载这个脚本:
wget -N --no-check-certificate https://raw.githubusercontent.com/Tsuk1ko/nhentai-one-key-downloader/master/nhentai-batch.sh && chmod +x nhentai-batch.sh然后用编辑器打开它,自己根据需要修改脚本开头的设置:
#setting off:0 on:1
zad=1 #下载完一个本子后自动压缩成zip
dsaz=1 #压缩完之后删除源文件
dldir="comics" #你想要把本子下载在哪个目录,相对/绝对路径均可开始使用
这个脚本有两种下载模式。
模式A
从一个nhentai搜索页面,地址类似于https://nhentai.net/search/?q=xxxxxx,或者其他的什么Tags/Artists/...页面下载本子,反正就是像下面这样的有很多本子结果的页面。
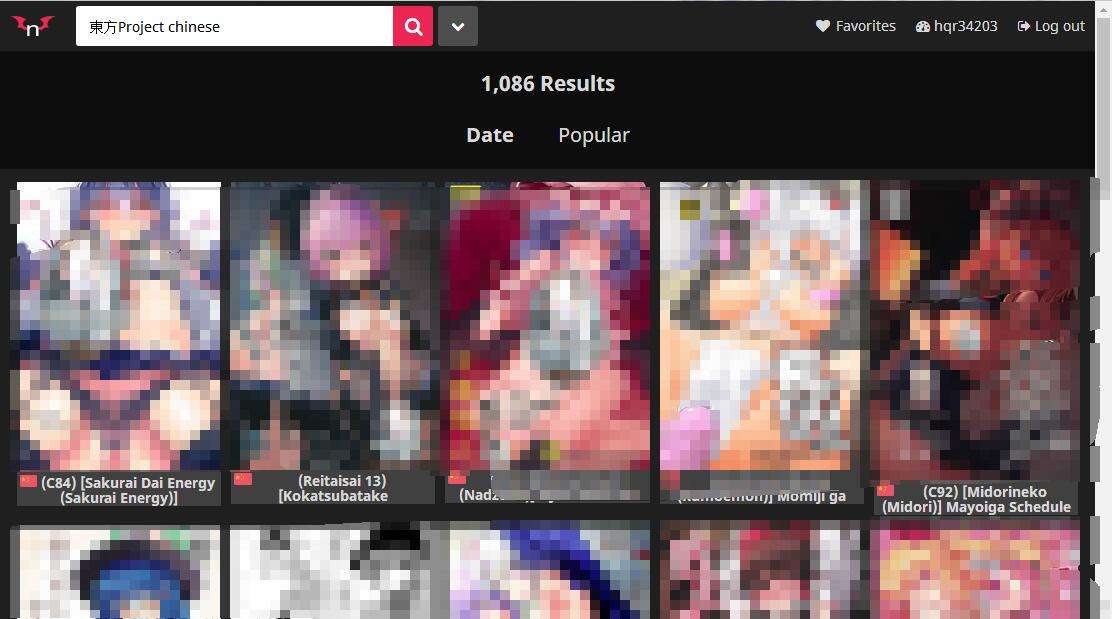
那就执行
./nhentai-batch.sh -a然后就输入这个网址接着回车就可以了,然后脚本会自动分析页面内的所有本子并且罗列出来并标上序号。如果你输入的网址有误会提示你。
然后会提示你有3种模式来下载本子:
- 白名单模式:下载你指定的本子
- 黑名单模式:除了你指定的本子之外,都下载
- 想个屁模式:我全下了!(列表中有重复的本子也不要紧,由于“查重”功能,只会下载一个)
如果你选择了模式1或者模式2,你需要输入你指定的本子的序号并以空格隔开,最后回车。
模式B
从一个本子详情页,类似https://nhentai.net/g/xxxxxx/网址的页面下载本子,也就是下图所示的这种页面。
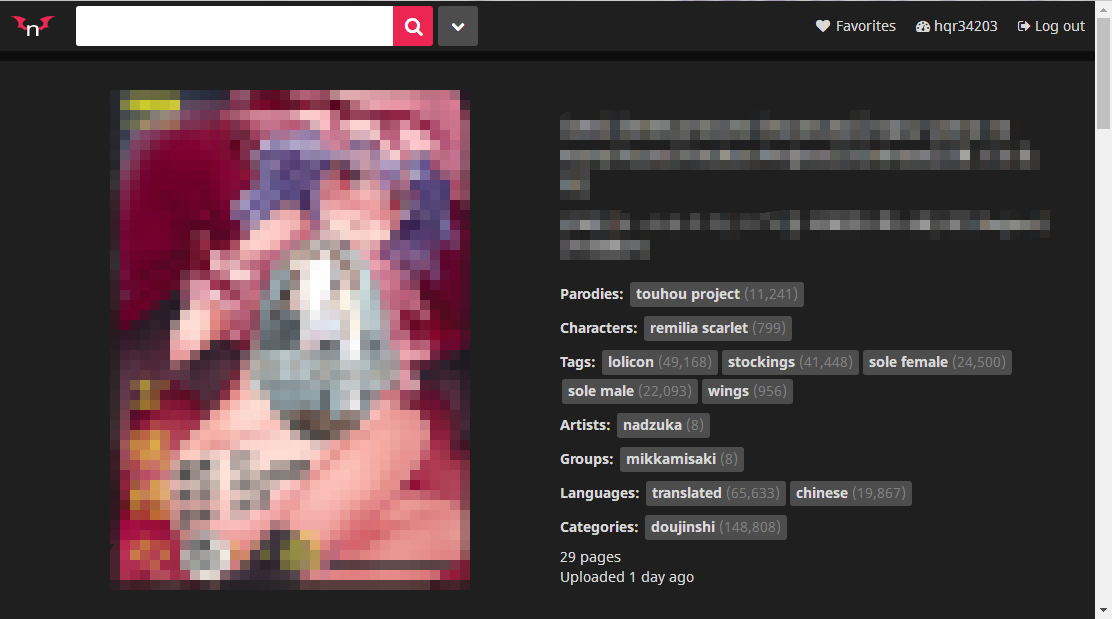
那就执行
./nhentai-batch.sh -b然后就会提示要你输入网址,按回车换行。你可以批量下载,即输入一个网址-换行-再输入一个网址-换行-……。当你输入一个空行的时候(即连续两次换行)即可结束输入,然后脚本会自动将所有你输入的网址里的本子下载下来。
其他功能
这个脚本带有查重功能和断点续传功能。
也就是说,如果你一个本子下到一半没下完就ctrl+c终止了脚本,那么你下次再下载同样的本子的时候会自动从上次断掉的地方开始下载(会自动检测并删除wget没有下载完全的文件并重新下载)。
已经下好了的图片会直接略过;如果文件夹内有和本子名称同名的压缩包(.zip),则也会判定为这个本子已经下过并跳过。
补充说明
如果在脚本完全运行完之前就ctrl+c结束了脚本,那么
- 在总下载目录里会遗留形如
.nhentai-temp-xxxxx的文件夹,删除即可 - 在没下完的本子目录里会遗留
.dl文件,这是用于记录本子下载进度的。如果你删除了,那么下次下载同一个本子的时候就无法识别 wget 是否完整下载了当时强制结束脚本时的那个图片。
TODO
开发网页程序(进行中)
版权声明:本文为原创文章,版权归 神代綺凜 所有。
本文链接:https://moe.best/technology/nhentai-downloader.html
所有原创文章采用 知识共享署名-非商业性使用 4.0 国际许可协议 进行许可。
您可以自由的转载和修改,但请务必注明文章来源并且不可用于商业目的。
#bg自行参考kirin酱,好像你的文章被盗了。连headpic链接都复制过去了。然而并没有headpic。想发个表情,pad上面就是点不开。泪
主要是看见那个视频里浏览器的头像。哈哈哈٩(。・ω・。)و
除非在自己电脑上登录之后获取cookie写curl参数
zip $zipcmd "${2}.zip" "$2" >/dev/null
这个倒是看到了..
但是不懂shell..
还有我想问假如..我想让它作为后台进程爬它的,我把链接关掉它也不会断..需要的时候再来查看...应该去看哪方面的知识....
zip想后台爬而且随时看的话可以用
screenscreen的使用yum install zip就好了
下面也许可以考虑..用Node来运行试试..就是不知道会是什么效果..有空也许尝试尝试...
我自己目前打算是用nodejs做解析(因为可以用jq选择器,爬虫好爬),下载独立做出一个php程序,因为我也觉得nodejs在下载这块会很麻烦
反正目前还处于做梦阶段(。
周末还在愉快的肝实验
我举个例子..
https://img1.thedoujin.com/images/ea/2d/ea2dc290fa6238e9bc4edde5816b8ac9.jpg
这是图片地址,直接在浏览器里访问就是403...这可是在浏览器环境下..UA肯定没问题的...
但是在浏览器里先访问这个..
http://thedoujin.com/index.php/pages/27548
再去直接浏览图片..就可以看到了..果然应该还是什么判断的原因吧..
如果按你这个说的最多就是cookie判断的问题,不过隐私模式下应该是隔离所有cookie的
于是试着用..Node,request('url').pipe(fs.createWriteStream('1.jpg'))也能取到..
但是..如图所示...
看不到的话..图片地址..https://s1.ax1x.com/2018/04/07/CPGjtH.png
其实到这里已经不影响写爬虫了..我只是单纯的好奇...
听你这么一说..我又试了下..把403的页面丢在那不管..没有去点原网页..一定时间后刷新会失去响应,再把链接取出来..再看就能在浏览器里显示图片了...挺迷的..