去年底除了忙期末还要忙找工作真是非常煎熬,不过总归是找到了~
Head Pic: 【FF14】「FF14」/「sabet@お仕事募集中」のイラスト [pixiv]
推荐
强烈推荐该汇总,含盖很多细节知识点
https://github.com/markyun/My-blog/tree/master/Front-end-Developer-Questions
网络
请求相关
请求头
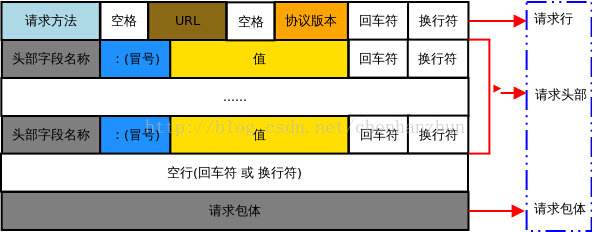
头部字段
Content-Length
Content-Length 首部告诉浏览器报文中实体主体的大小。这个大小是包含了内容编码的,比如对文件进行了 gzip 压缩,Content-Length 就是压缩后的大小,而不是原始大小
Content-Length 对于长连接是必不可少的,长连接代表在连接期间会有多个 http 请求响应在排队,而服务器不能够关闭连接,客户端只能通过 Content-Length 知道一条报文在哪里结束,下一条报文在哪里开始。
除非使用了分块编码Transfer-Encoding: chunked,否则响应头必须包含 Content-Length 。
请求方法
| 方法 | 描述 |
|---|---|
| GET | 请求指定的页面信息,并返回实体主体。 |
| HEAD | 类似于GET请求,只不过返回的响应中没有具体的内容,用于获取报头 |
| POST | 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST请求可能会导致新的资源的建立和/或已有资源的修改。 |
| PUT | 从客户端向服务器传送的数据取代指定的文档的内容。 |
| DELETE | 请求服务器删除指定的页面。 |
| CONNECT | HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。 |
| OPTIONS | 允许客户端查看服务器的性能。 |
| TRACE | 回显服务器收到的请求,主要用于测试或诊断。 |
常见状态码
| 分类 | 分类描述 |
|---|---|
| 1** | 信息,服务器收到请求,需要请求者继续执行操作 |
| 2** | 成功,操作被成功接收并处理 |
| 3** | 重定向,需要进一步的操作以完成请求 |
| 4** | 客户端错误,请求包含语法错误或无法完成请求 |
| 5** | 服务器错误,服务器在处理请求的过程中发生了错误 |
| 状态码 | 状态码英文名称 | 中文描述 |
|---|---|---|
| 200 | OK | 请求成功。一般用于GET与POST请求 |
| 301 | Moved Permanently | 永久移动。请求的资源已被永久的移动到新URI,返回信息会包括新的URI,浏览器会自动定向到新URI。今后任何新的请求都应使用新的URI代替 |
| 302 | Found | 临时移动。与301类似。但资源只是临时被移动。客户端应继续使用原有URI |
| 304 | Not Modified | 未修改。所请求的资源未修改,服务器返回此状态码时,不会返回任何资源。客户端通常会缓存访问过的资源,通过提供一个头信息指出客户端希望只返回在指定日期之后修改的资源 |
| 307 | Temporary Redirect | 临时重定向。与302类似。使用GET请求重定向 |
| 400 | Bad Request | 客户端请求的语法错误,服务器无法理解 |
| 401 | Unauthorized | 请求要求用户的身份认证 |
| 403 | Forbidden | 服务器理解请求客户端的请求,但是拒绝执行此请求 |
| 404 | Not Found | 服务器无法根据客户端的请求找到资源(网页)。通过此代码,网站设计人员可设置"您所请求的资源无法找到"的个性页面 |
| 413 | Request Entity Too Large | 由于请求的实体过大,服务器无法处理,因此拒绝请求。为防止客户端的连续请求,服务器可能会关闭连接。如果只是服务器暂时无法处理,则会包含一个Retry-After的响应信息 |
| 414 | Request-URI Too Large | 请求的URI过长(URI通常为网址),服务器无法处理 |
| 429 | Too Many Requests | 请求速度超过服务端限制 |
| 500 | Internal Server Error | 服务器内部错误,无法完成请求 |
| 502 | Bad Gateway | 作为网关或者代理工作的服务器尝试执行请求时,从远程服务器接收到了一个无效的响应 |
| 503 | Service Unavailable | 由于超载或系统维护,服务器暂时的无法处理客户端的请求。延时的长度可包含在服务器的Retry-After头信息中 |
| 504 | Gateway Time-out | 充当网关或代理的服务器,未及时从远端服务器获取请求 |
TCP 三次握手
- 建立连接时,客户端发送 SYN 包(SYN=j)到服务器,并进入 SYN_SENT 状态,等待服务器确认
- 服务器收到 SYN 包,必须确认客户的 SYN(ACK=j+1),同时自己也发送一个 SYN 包(SYN=k),即 SYN+ACK 包,此时服务器进入 SYN_RECV 状态
- 客户端收到服务器的 SYN+ACK 包,向服务器发送确认包 ACK(ACK=k+1),此包发送完毕,客户端和服务器进入 ESTABLISHED(TCP连接成功)状态,完成三次握手
跨域
同源策略
同源策略/SOP(Same origin policy)是一种约定,由Netscape公司1995年引入浏览器,它是浏览器最核心也最基本的安全功能,如果缺少了同源策略,浏览器很容易受到XSS、CSFR等攻击。所谓同源是指“协议+域名+端口”三者相同,即便两个不同的域名指向同一个ip地址,也非同源。
同源策略限制以下几种行为:
- Cookie、LocalStorage 和 IndexDB 无法读取
- DOM 和 Js 对象无法获得
- AJAX 请求不能发送
跨域解决方案
-
通过 jsonp(只能 GET)
-
document.domain + iframe(仅限主域相同,子域不同)
-
location.hash + iframe
-
window.name + iframe
-
postMessage
-
跨域资源共享(CORS)
服务端 Header: Access-Control-Allow-Origin
-
nginx 反向代理
nodejs 中间件代理
- WebSocket 协议
储存
| 特性 | Cookie | localStorage | sessionStorage |
|---|---|---|---|
| 数据的生命期 | 一般由服务器生成,可设置失效时间。如果在浏览器端生成 Cookie,默认是关闭浏览器后失效 | 除非被清除,否则永久保存 | 仅在当前会话下有效, 关闭页面或浏览器后被清除 |
| 存放数据大小 | 4K左右 | 一般为5MB | 同左 |
| 与服务器端通信 | 每次都会携带在 HTTP 头中,如果使用 cookie 保存过多数据会带来性能问题 | 仅在客户端(即浏览器)中保存,不参与和服务器的通信 | 同左 |
| 易用性 | 需要程序员自己封装,原生的 Cookie 接口不友好 | 原生接口可以接受,亦可再次封装来对 Object 和 Array 有更好的支持 | 同左 |
HTTP/2 新特性
https://www.jianshu.com/p/67c541a421f9
- 二进制帧层:减小体积,提高传输性能
- 流、消息、帧
- 请求和响应的多路复用:由于二进制帧的出现,帧可以在流中不按序传输,到达后再组装,解决了 HTTP/1.x 可能出现的头部阻塞问题
- 流具有优先级
- 每个源仅需要一个连接:充分利用 TCP,减小整体协议的头部
- 流量控制
- 头部压缩
HTTPS 相关
SSL 连接建立过程
SSL 使用不对称+对称加密
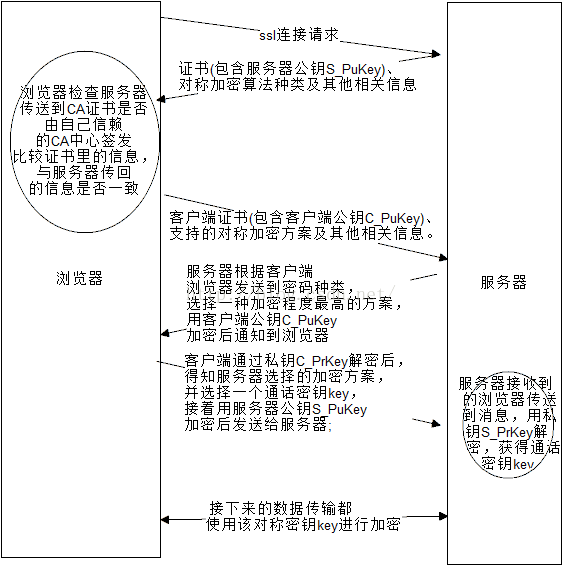
对公钥进行认证
黑客可以替换你的公钥,然后用他的私钥做数字签名给你发信息,而你用黑客伪造的公钥能成功验证,会让你误认为消息来源没变。
这种情况下需要CA(证书中心certificate authority)对公钥进行认证。证书中心用自己的私钥,对信息发送者的公钥和一些相关信息一起加密,生成"数字证书"(Digital Certificate)。
攻击
CSRF 跨站请求伪造

防范方法:
在要提交的表单中加入一个一次性验证字段,这个字段由服务端生成并且储存于 session 中,服务端接收到表单提交请求后对字段进行验证。
相似的解决方案还有“双提交”Cookie,在 ajax 提交 POST 请求时将 Cookie 一并作为表单字段提交,因为读取 Cookie 只有在信任域内才能做到。
XSS 跨站脚本攻击
XSS是指恶意攻击者利用网站没有对用户提交数据进行转义处理或者过滤不足的缺点,进而添加一些代码,嵌入到web页面中去,使别的用户访问都会执行相应的嵌入代码,从而盗取用户资料、利用用户身份进行某种动作或者对访问者进行病毒侵害的一种攻击方式。
防范方法:不可信任任何用户提交的数据,必须对部分敏感字符进行转义、过滤。
协商缓存与强缓存
强制缓存
强制缓存整体流程比较简单,就是在第一次访问服务器取到数据之后,在过期时间之内不会再去重复请求。实现这个流程的核心就是如何知道当前时间是否超过了过期时间。
强制缓存的过期时间通过第一次访问服务器时返回的响应头获取。在 http 1.0 和 http 1.1 版本中通过不同的响应头字段实现。
http 1.0
在 http 1.0 版本中,强制缓存通过 Expires 响应头来实现。 expires 表示未来资源会过期的时间。也就是说,当发起请求的时间超过了 expires 设定的时间,即表示资源缓存时间到期,会发送请求到服务器重新获取资源。而如果发起请求的时间在 expires 限定的时间之内,浏览器会直接读取本地缓存数据库中的信息(from memory or from disk),两种方式根据浏览器的策略随机获取。
http 1.1
在 http 1.1 版本中,强制缓存通过 Cache-Control 响应头来实现。Cache-Control 拥有多个值:
private:客户端可以缓存
public:客户端和代理服务器均可缓存;
max-age=xxx:缓存的资源将在 xxx 秒后过期;
no-cache:需要使用协商缓存来验证是否过期;
no-store:不可缓存
最常用的字段就是 max-age=xxx ,表示缓存的资源将在 xxx 秒后过期。一般来说,为了兼容,两个版本的强制缓存都会被实现。
总结
强制缓存只有首次请求才会跟服务器通信,读取缓存资源时不会发出任何请求,资源的 Status 状态码为 200,资源的 Size 为 from memory 或者 from disk ,http 1.1 版本的实现优先级会高于 http 1.0 版本的实现。
协商缓存
协商缓存与强制缓存的不同之处在于,协商缓存每次读取数据时都需要跟服务器通信,并且会增加缓存标识。在第一次请求服务器时,服务器会返回资源,并且返回一个资源的缓存标识,一起存到浏览器的缓存数据库。当第二次请求资源时,浏览器会首先将缓存标识发送给服务器,服务器拿到标识后判断标识是否匹配,如果不匹配,表示资源有更新,服务器会将新数据和新的缓存标识一起返回到浏览器;如果缓存标识匹配,表示资源没有更新,并且返回 304 状态码,浏览器就读取本地缓存服务器中的数据。
在 http 协议的 1.0 和 1.1 版本中也有不同的实现方式。
http 1.0
在 http 1.0 版本中,第一次请求资源时服务器通过 Last-Modified 来设置响应头的缓存标识,并且把资源最后修改的时间作为值填入,然后将资源返回给浏览器。在第二次请求时,浏览器会首先带上 If-Modified-Since 请求头去访问服务器,服务器会将 If-Modified-Since 中携带的时间与资源修改的时间匹配,如果时间不一致,服务器会返回新的资源,并且将 Last-Modified 值更新,作为响应头返回给浏览器。如果时间一致,表示资源没有更新,服务器返回 304 状态码,浏览器拿到响应状态码后从本地缓存数据库中读取缓存资源。
这种方式有一个弊端,就是当服务器中的资源增加了一个字符,后来又把这个字符删掉,本身资源文件并没有发生变化,但修改时间发生了变化。当下次请求过来时,服务器也会把这个本来没有变化的资源重新返回给浏览器。
http 1.1
在 http 1.1 版本中,服务器通过 Etag 来设置响应头缓存标识。Etag 的值由服务端生成。在第一次请求时,服务器会将资源和 Etag 一并返回给浏览器,浏览器将两者缓存到本地缓存数据库。在第二次请求时,浏览器会将 Etag 信息放到 If-None-Match 请求头去访问服务器,服务器收到请求后,会将服务器中的文件标识与浏览器发来的标识进行对比,如果不相同,服务器返回更新的资源和新的 Etag ,如果相同,服务器返回 304 状态码,浏览器读取缓存。
总结
协商缓存每次请求都会与服务器交互,第一次是拿数据和标识的过程,第二次开始,就是浏览器询问服务器资源是否有更新的过程。每次请求都会传输数据,如果命中缓存,则资源的 Status 状态码为 304 而不是 200 。同样的,一般来讲为了兼容,两个版本的协商缓存都会被实现,http 1.1 版本的实现优先级会高于 http 1.0 版本的实现。
HTML
页面渲染
渲染过程
不同的浏览器工作方式是不一样的,下面的图表提供了渲染时的共同实现,一旦他们已经下载好了你页面的代码,多半都会通过浏览器这样实现。

重排和重绘
无论何时总会有一个初始化的页面布局伴随着一次绘制(除非你希望你的页面是空白的)。之后,每一次改变用于构建渲染树的信息都会导致以下至少一个的行为:
- 部分渲染树(或者整个渲染树)需要重新分析并且节点尺寸需要重新计算。这被称为重排。注意这里至少会有一次重排-初始化页面布局。
- 由于节点的几何属性发生改变或者由于样式发生改变,例如改变元素背景色时,屏幕上的部分内容需要更新。这样的更新被称为重绘。
重排和重绘代价是高昂的,它们会破坏用户体验,并且让UI展示非常迟缓。
什么情况会触发重排和重绘
任何改变用来构建渲染树的信息都会导致一次重排或重绘。
- 添加、删除、更新DOM节点
- 通过
display: none隐藏一个DOM节点 - 通过
visibility: hidden隐藏一个DOM节点:只触发重绘 - 移动或者给页面中的DOM节点添加动画
- 添加一个样式表,调整样式属性
- 当仅改变颜色时只触发重绘
- 用户行为,例如调整窗口大小,改变字号,或者滚动。
最小化重排和重绘
通过减少重排/重绘的负面影响来提高用户体验的最简单方式就是,尽可能少的去使用他们的同时尽可能少的请求样式信息,这样浏览器就可以优化重排。
- 不要逐个变样式。对于静态页面来说,明智且兼具可维护性的做法是改变类名而不是样式。对于动态改变的样式来说,相较每次微小修改都直接触及元素,更好的办法是统一在
cssText变量中编辑。
// bad
var left = 10,
top = 10;
el.style.left = left + "px";
el.style.top = top + "px";
// better
el.className += " theclassname";
// 当top和left的值是动态计算而成时...
// better
el.style.cssText += "; left: " + left + "px; top: " + top + "px;";- “离线”地批量改变和表现DOM。“离线”意味着不在当前的DOM树中做修改。你可以:
- 通过
documentFragment来保留临时变动。 - 复制你即将更新的节点,在副本上工作,然后将之前的节点和新节点交换。
- 通过
display:none属性隐藏元素(只有一次重排重绘),添加足够多的变更后,通过display属性显示(另一次重排重绘)。通过这种方式即使大量变更也只触发两次重排。
- 通过
- 不要频繁计算样式。如果你有一个样式需要计算,只取一次,将它缓存在一个变量中并且在这个变量上工作。
// no-no!
for(big; loop; here) {
el.style.left = el.offsetLeft + 10 + "px";
el.style.top = el.offsetTop + 10 + "px";
}
// better
var left = el.offsetLeft,
top = el.offsetTop,
esty = el.style;
for(big; loop; here) {
left += 10;
top += 10;
esty.left = left + "px";
esty.top = top + "px";
}- 通常情况下,考虑一下渲染树和变更后需要重新验证的消耗。举个例子,使用绝对定位会使得该元素单独成为渲染树中 body 的一个子元素,所以当你对其添加动画时,它不会对其它节点造成太多影响。当你在这些节点上放置这个元素时,一些其它在这个区域内的节点可能需要重绘,但是不需要重排。
性能优化

CSS
单位
- px:像素
- em:相对大小,默认 1em = 16px
- rem:相对 HTML 根元素的字体大小,优点是只修改根元素就能成比例地调整所有字体大小,并且可以避免字体大小逐层复合的连锁反应
模型
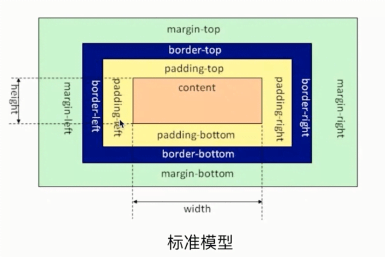
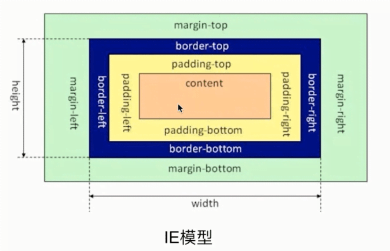
/* 标准模型 */
box-sizing: content-box;
/*IE模型*/
box-sizing: border-box;边距重叠


边距重叠解决方案 (BFC)
- float 属性不为 none(脱离文档流)
- position 为 absolute 或 fixed
- display 为 inline-block, table-cell, table-caption, flex, inine-flex
- overflow 不为 visible
- 根元素

元素的居中
行内元素(文字)
.xxx {
text-align: center;
vertical-align: middle;
}块状元素
-
绝对定位 + 负margin
.xxx { position: absolute; width: 200px; height: 200px; top: 50%; left: 50%; margin-top: -100px; /*自身的一半*/ margin-left: -100px; } -
绝对定位 + margin:auto
.xxx { position: absolute; width: 200px; height: 200px; top: 0; left: 0; bottom: 0; right: 0; margin: auto; } -
Flex(给父元素设置)
.father { display: flex; justify-content: center; align-items: center; } -
Transform
.xxx { position: absolute; top: 50%; left: 50%; transform: translate(-50%,-50%); } -
Table
.father { display: table; } .xxx { text-align: center; vertical-align: middle; display: table-cell; }
清除浮动
<div class="outer clearfix">
<div class="float-left">left</div>
<div class="float-right">right</div>
<div class="clear"></div>
</div>-
添加新元素,应用
clear: both;.clear { clear: both; }优点:简单,代码少,浏览器兼容性好。
缺点:需要添加无语义的 html 元素,代码不够优雅,后期不容易维护。
-
给父元素应用
overflow: hidden,另外在 IE6 中还需要触发 hasLayout ,可以为父元素设置容器宽高或设置zoom: 1原理是触发了浮动元素的父元素的 BFC (Block Formatting Contexts, 块级格式化上下文),使到该父元素可以包含浮动元素
.outer { overflow: hidden; *zoom: 1; } -
使用伪元素
.clearfix::after { display: block; clear: both; content: ""; }
Flex 布局
采用Flex布局的元素,称为Flex容器(flex container),简称”容器”。它的所有子元素自动成为容器成员,称为Flex项目(flex item),简称”项目”。

容器默认存在两根轴:水平的主轴(main axis)和垂直的交叉轴(cross axis)。主轴的开始位置(与边框的交叉点)叫做main start,结束位置叫做main end;交叉轴的开始位置叫做cross start,结束位置叫做cross end。
项目默认沿主轴排列。单个项目占据的主轴空间叫做main size,占据的交叉轴空间叫做cross size。
容器属性
-
flex-direction 决定主轴的方向(即项目的排列方向)
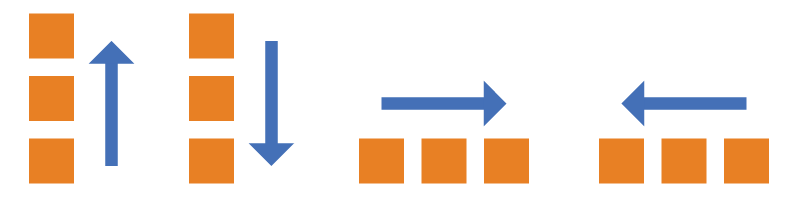
- row(默认值):主轴为水平方向,起点在左端。
- row-reverse:主轴为水平方向,起点在右端。
- column:主轴为垂直方向,起点在上沿。
- column-reverse:主轴为垂直方向,起点在下沿。
-
flex-wrap 决定如何换行
-
nowrap(默认):不换行

-
wrap:换行,第一行在上方

-
wrap-reverse:换行,第一行在下方

-
-
flex-flow 上述两个的简写形式,默认值为
row nowrap -
justify-content 定义项目在主轴上的对齐方式

-
align-items 定义项目在交叉轴上如何对齐,默认
flex-start
-
align-content 定义了多根轴线的对齐方式,如果项目只有一根轴线则该属性不起作用,默认
stretch
项目属性
-
order 定义项目的排列顺序:数值越小,排列越靠前,默认为
0 -
flex-grow 定义项目的放大比例,默认为
0,即如果存在剩余空间,也不放大
-
flex-shrink 定义了项目的缩小比例,默认为
1,即如果空间不足,该项目将缩小
-
flex-basis 定义了在分配多余空间之前,项目占据的主轴空间,类似
width或height,默认auto -
flex 是上面三个属性的简写,默认值
0 1 auto - align-self 允许单个项目有与其他项目不一样的对齐方式,可覆盖
align-items属性,默认值为auto
Javascript
部分值得一提的函数(常用的烂熟的就不写了)
Array
| 方法 | 语法 | 描述 |
|---|---|---|
| entries() | array.entries() | 返回数组的可迭代对象,该对象包含数组的键值对 |
| every() | array.every(function(currentValue, index, arr), thisValue) | 检测数值元素的每个元素是否都符合条件 |
| fill() | array.fill(value, start, end) | 使用一个固定值来填充数组 |
| filter() | array.filter(function(currentValue, index, arr), thisValue) | 检测数值元素,并返回符合条件所有元素的数组 |
| find() | array.find(function(currentValue, index, arr), thisValue) | 返回第一个符合传入测试(函数)条件的数组元素 |
| findIndex() | array.findIndex(function(currentValue, index, arr), thisValue) | 返回第一个符合传入测试(函数)条件的数组元素索引 |
| from() | Array.from(object, mapFunction, thisValue) | 通过给定的对象中创建一个数组 |
| map() | array.map(function(currentValue, index, arr), thisValue) | 通过指定函数处理数组的每个元素,并返回处理后的数组,不会改变原数组 |
| pop() | array.pop() | 删除并返回数组的最后一个元素 |
| reduce() | array.reduce(function(total, currentValue, currentIndex, arr), initialValue) | 将数组元素计算为一个值(从左到右) |
| reduceRight() | array.reduceRight(function(total, currentValue, currentIndex, arr), initialValue) | 将数组元素计算为一个值(从右到左) |
| reverse() | array.reverse() | 反转数组的元素顺序 |
| shift() | array.shift() | 删除并返回数组的第一个元素 |
| slice() | array.slice(start, end) | 选取数组的的一部分,并返回一个新数组 |
| some() | array.some(function(currentValue, index, arr), thisValue) | 检测数组元素中是否有元素符合指定条件 |
| sort() | array.sort(sortfunction) sortfunction(a, b){return a-b} //升序 |
对数组的元素进行排序(默认均以字符串的规则进行排序) |
| splice() | array.splice(index, howmany, item1, ....., itemX) | 从数组中 index 开始删除 howmany 个元素然后插入新元素 |
| unshift() | array.unshift(item1, item2, ..., itemX) | 向数组的开头添加一个或更多元素,并返回新的长度 |
String
| 方法 | 语法 | 描述 |
|---|---|---|
| fromCharCode() | String.fromCharCode(n1, n2, ..., nX) | 将 Unicode 编码转为字符。 |
| match() | string.match(regexp) | 查找找到一个或多个正则表达式的匹配,返回数组 |
| replace() | string.replace(searchvalue, newvalue) | 在字符串中查找匹配的子串, 并替换与正则表达式匹配的子串,searchvalue 可以是正则表达式 |
| search() | string.search(searchvalue) | 查找与正则表达式或字符串相匹配的值,返回匹配的起始位置 |
| slice() | string.slice(start, end) | 提取字符串的片断,并在新的字符串中返回被提取的部分,end 可以为负数(从尾部算起) |
| split() | string.split(separator, limit) | 把字符串按 separator 分割为字符串数组,最多 limit 个 |
| substr() | string.substr(start, length) | 从起始索引号提取字符串中指定数目的字符 |
| substring() | string.substring(from, to) | 提取字符串中两个指定的索引号之间的字符 |
| trim() | 去除字符串两边的空白 |
原型规则
-
所有的函数,都有一个
prototype(显式原型)属性,属性值是一个普通的对象 -
所有的引用类型(数组、对象、函数),
__proto__属性值(隐式原型)指向它的构造函数的prototype属性值 -
当试图得到一个对象的某个属性时,如果这个对象本身没有这个属性,那么会去它的
__proto__(即它的构造函数的prototype)中寻找 -
instanceof:判断 引用类型 属于哪个 构造函数 的方法(如果是 基本类型 则一定false)与
typeof对比:一个一元运算,返回一个字符串,说明运算数的类型,一般只返回number、string、boolean、object、function和undefined(当运算数未定义时)Object instanceof Object //true Object.__proto__ === Function.prototype Function.prototype.__proto__ === Object.prototype //特别地 Object.prototype.__proto__ === null Function instanceof Function //true Function.__proto__ === Function.prototype
this 指向
在闭包中,由于匿名函数的执行具有全局性,所以其 this 会指向 window
var myNumber = {
value: 1,
add: function (i) {
var helper = function (i) {
console.log(this);
this.value += i;
}
helper(i);
}
}
myNumber.add(1);例如此代码无法实现 value 加1
修改方法
-
使用另一个变量保存 this
var myNumber = { value: 1, add: function (i) { var that = this; //定义变量that用于保存上层函数的this对象 var helper = function (i) { console.log(that); that.value += i; } helper(i); } } myNumber.add(1); -
使用 apply 或 call 改变 this 指向
var myNumber = { value: 1, add: function (i) { var helper = function (i) { this.value += i; } helper.apply(this, [i]); //使用apply改变helper的this对象指向 } } myNumber.add(1); -
使用 bind 绑定 this
var myNumber = { value: 1, add: function (i) { var helper = function (i) { this.value += i; }.bind(this, i); //使用bind绑定,它返回的是对函数的引用,不会立即执行 helper(i); } } myNumber.add(1);
运行机制
JavaScript语言的一大特点就是单线程,也就是说,同一个时间只能做一件事。那么,为什么JavaScript不能有多个线程呢?这样能提高效率啊。
JavaScript的单线程,与它的用途有关。作为浏览器脚本语言,JavaScript的主要用途是与用户互动,以及操作DOM。这决定了它只能是单线程,否则会带来很复杂的同步问题。比如,假定JavaScript同时有两个线程,一个线程在某个DOM节点上添加内容,另一个线程删除了这个节点,这时浏览器应该以哪个线程为准?
所以,为了避免复杂性,从一诞生,JavaScript就是单线程,这已经成了这门语言的核心特征,将来也不会改变。
为了利用多核CPU的计算能力,HTML5提出Web Worker标准,允许JavaScript脚本创建多个线程,但是子线程完全受主线程控制,且不得操作DOM。所以,这个新标准并没有改变JavaScript单线程的本质。
任务队列
单线程就意味着,所有任务需要排队,前一个任务结束,才会执行后一个任务。如果前一个任务耗时很长,后一个任务就不得不一直等着。
JavaScript语言的设计者意识到,这时主线程完全可以不管IO设备,挂起处于等待中的任务,先运行排在后面的任务。等到IO设备返回了结果,再回过头,把挂起的任务继续执行下去。
于是,所有任务可以分成两种,一种是同步任务(synchronous),另一种是异步任务(asynchronous)。同步任务指的是,在主线程上排队执行的任务,只有前一个任务执行完毕,才能执行后一个任务;异步任务指的是,不进入主线程、而进入"任务队列"(task queue)的任务,只有"任务队列"通知主线程,某个异步任务可以执行了,该任务才会进入主线程执行。
异步执行的运行机制如下:
-
所有同步任务都在主线程上执行,形成一个执行栈(execution context stack)。
-
主线程之外,还存在一个"任务队列"(task queue)。只要异步任务有了运行结果,就在"任务队列"之中放置一个事件。
-
一旦"执行栈"中的所有同步任务执行完毕,系统就会读取"任务队列",看看里面有哪些事件。那些对应的异步任务,于是结束等待状态,进入执行栈,开始执行。
-
主线程不断重复上面的第三步。
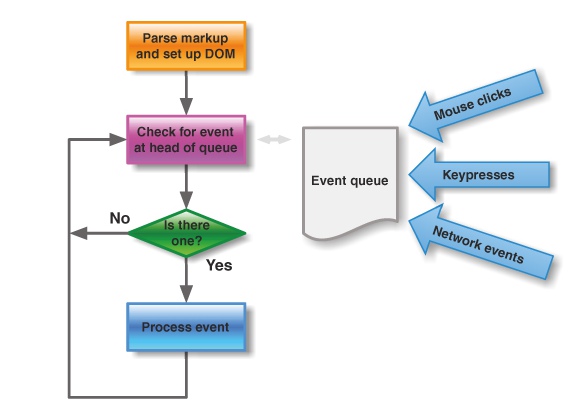
Event Loop
主线程从"任务队列"中读取事件,这个过程是循环不断的,所以整个的这种运行机制又称为Event Loop(事件循环)。
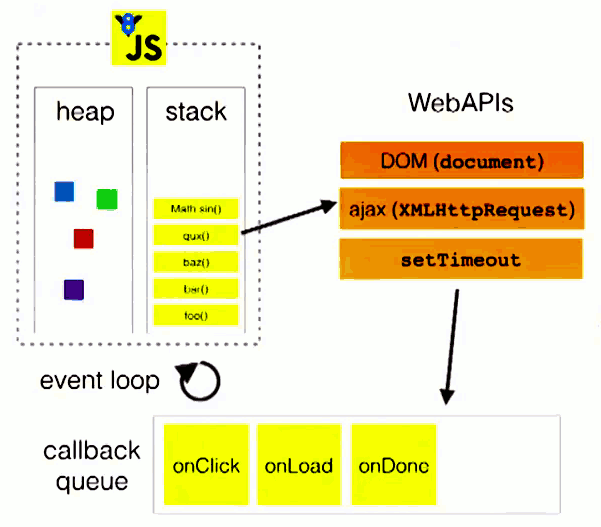
主线程运行的时候,产生堆(heap)和栈(stack),栈中的代码调用各种外部API,它们在"任务队列"中加入各种事件(click,load,done)。只要栈中的代码执行完毕,主线程就会去读取"任务队列",依次执行那些事件所对应的回调函数。
执行栈中的代码(同步任务),总是在读取"任务队列"(异步任务)之前执行,例如以下两段代码是等价的:
var req = new XMLHttpRequest();
req.open('GET', url);
req.onload = function () {};
req.onerror = function () {};
req.send();var req = new XMLHttpRequest();
req.open('GET', url);
req.send();
req.onload = function () {};
req.onerror = function () {};指定回调函数的部分(onload 和 onerror),在 send() 方法的前面或后面无关紧要,因为它们属于执行栈的一部分,系统总是执行完它们,才会去读取"任务队列"。
宏任务与微任务
setTimeout(function () {
console.log('1');
});
new Promise(function (resolve) {
console.log('2');
resolve();
}).then(function () {
console.log('3');
});
console.log('4');代码运行顺序:2 4 3 1
宏任务:包括整体代码、setTimeout、setInterval
微任务:Promise、process.nextTick
异步有一个机制,就是遇到宏任务,先执行宏任务,将宏任务放入 eventqueue,然后在执行微任务,将微任务放入 eventqueue,并且这两个队列不是一个队列。当你往外拿的时候,先从微任务队列里拿回掉函数,然后再从宏任务队列里拿回掉函数。
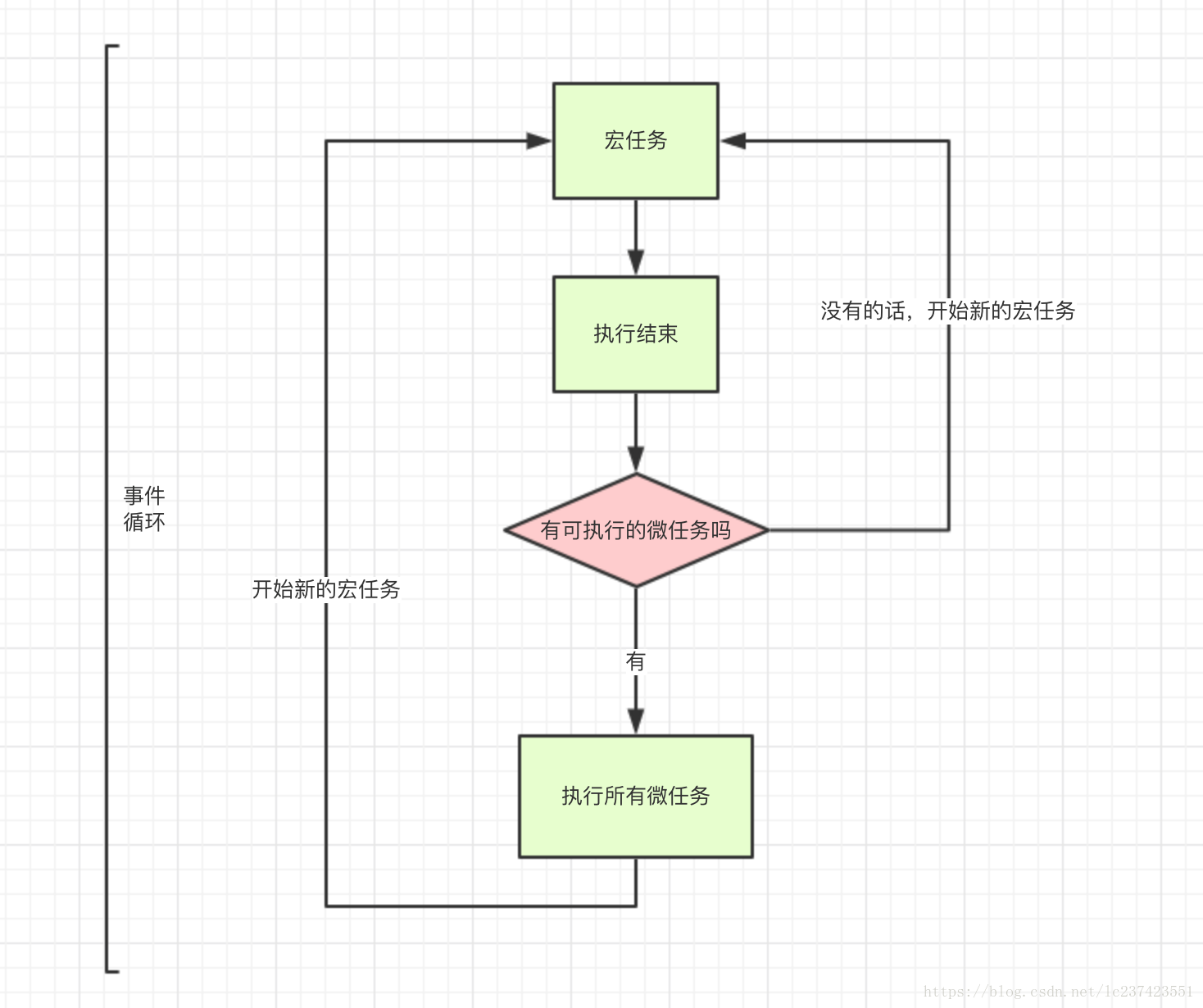
事件
事件捕获
通俗的理解就是,当鼠标点击或者触发dom事件时,浏览器会从根节点开始由外到内进行事件传播,即点击了子元素,如果父元素通过事件捕获方式注册了对应的事件的话,会先触发父元素绑定的事件。
事件冒泡
与事件捕获恰恰相反,事件冒泡顺序是由内到外进行事件传播,直到根节点。
事件传播
DOM 标准事件流的触发的先后顺序为:先捕获再冒泡,即当触发dom事件时,会先进行事件捕获,捕获到事件源之后通过事件传播进行事件冒泡。
element.addEventListener(event, function, useCapture)第一个参数是需要绑定的事件
第二个参数是触发事件后要执行的函数
第三个参数默认值是false,表示在事件冒泡阶段调用事件处理函数;如果参数为true,则表示在事件捕获阶段调用处理函数。
bind / apply / call
bind
bind()用于创建一个函数,并将这个函数的this值绑定到某个对象
this.num = 9;
var mymodule = {
num: 81,
getNum: function() {
console.log(this.num);
}
};
mymodule.getNum(); // 81
var getNum = mymodule.getNum;
getNum(); // 9, 因为在这个例子中,"this"指向全局对象
var boundGetNum = getNum.bind(mymodule);
boundGetNum(); // 81apply / call
作用完全一样,只是参数接收方式不一样
func.call(this, arg1, arg2);
func.apply(this, [arg1, arg2])
//在ES6中可以利用rest参数
func.call(this, ...args);Promise
then 的第二个参数和 catch 的区别
getJSON("/post/1.json").then(
post => getJSON(post.commentURL)
).then(
comments => console.log("resolved: ", comments),
err => console.log("rejected: ", err)
);在第一个then()中的异常可以被第二个then()的第二个参数指定的回调函数处理,但第二个then()中第一个参数指定的回调函数如果产生了异常,则不能被第二个参数指定的回调函数处理
如果在最后使用catch()捕获处理,则没有这个问题
all 和 rase
Promise.all和Promise.rase方法都用于将多个 Promise 实例,包装成一个新的 Promise 实例
const p_all = Promise.all([p1, p2, p3]);
const p_rase = Promise.rase([p1, p2, p3]);其区别是:
Promise.all- 只有
p1、p2、p3的状态都变成fulfilled,p_all的状态才会变成fulfilled,此时p1、p2、p3的返回值组成一个数组,传递给p_all的回调函数 - 只要
p1、p2、p3之中有一个被rejected,p_all的状态就变成rejected,此时第一个被reject的实例的返回值,会传递给p_all的回调函数。
- 只有
Promise.rase- 只要
p1、p2、p3之中有一个实例率先改变状态,p_rase的状态就跟着改变,那个率先改变的 Promise 实例的返回值,就传递给p的回调函数
- 只要
Ajax
let xmlhttp = new XMLHttpRequest();
xmlhttp.open("GET","index.html",true); //method, url, async
xmlhttp.send();属性和事件
ReadyState 属性
| 取值 | 描述 |
|---|---|
| 0 | 描述一种"未初始化"状态;此时,已经创建一个 XMLHttpRequest 对象,但是还没有初始化。 |
| 1 | 描述一种"发送"状态;此时,代码已经调用了 open() 方法并且 XMLHttpRequest 已经准备好把一个请求发送到服务器。 |
| 2 | 描述一种"发送"状态;此时,已经通过 send() 方法把一个请求发送到服务器端,但是还没有收到一个响应。 |
| 3 | 描述一种"正在接收"状态;此时,已经接收到 HTTP 响应头部信息,但是消息体部分还没有完全接收结束。 |
| 4 | 描述一种"已加载"状态;此时,响应已经被完全接收。 |
onreadystatechange 事件
无论 readyState 值何时发生改变,XMLHttpRequest 对象都会激发一个 readystatechange 事件。
responseText 属性
这个 responseText 属性包含客户端接收到的 HTTP 响应的文本内容。当 readyState 值为0、1或2时, responseText 包含一个空字符串。当 readyState 值为3(正在接收)时,响应中包含客户端还未完成的响应信息。当 readyState 为4(已加载)时,该 responseText 包含完整的响应信息。
responseXML 属性
如果 Content-Type 头部并不包含 text/xml、application/xml 或以 +xml 结尾的这些媒体类型之一,那么 responseXML 的值为 null。无论何时,只要 readyState 值不为4,那么该 responseXML 的值也为null。
status / statusText 属性
这个属性描述了 HTTP 状态代码以及状态码文本。仅当 readyState 值为3(正在接收中)或4(已加载)时,这个属性才可用。当 readyState 的值小于3时试图存取 status 的值将引发一个异常。
函数节流与函数防抖
-
函数节流:指定时间间隔内只会执行一次任务
- 函数防抖:任务频繁触发的情况下,只有任务触发的间隔超过指定间隔的时候,任务才会执行
函数节流 (throttle)
例如你需要监听window的scroll事件,但连续滚动时每一次微小的滚动都会触发一次事件,使得函数被高频率调用,此时你希望在一个固定时间段内只执行一次函数中的操作
函数的节流就是通过闭包保存一个标记(canRun = true),在函数的开头判断这个标记是否为 true,如果为 true 的话就继续执行函数,否则 return 掉,判断完标记后立即把这个标记设为 false,然后把外部传入的函数的执行包在一个 setTimeout 中,最后在 setTimeout执行完毕后再把标记设置为 true(这里很关键),表示可以执行下一次的循环了。
function throttle(fn, interval = 300) {
let canRun = true; //标记
return function () {
if (!canRun) return;
canRun = false;
setTimeout(() => {
fn.apply(this, arguments);
canRun = true;
}, interval);
};
}函数防抖 (debounce)
以用户注册时验证用户名是否被占用为例,如今很多网站为了提高用户体验,不会再输入框失去焦点的时候再去判断用户名是否被占用,而是在输入的时候就在判断这个用户名是否已被注册。
如果每次输入一个字符就验证一次,不仅对服务器的压力增大了,对用户体验也未必比原来的好。而理想的做法应该是这样的,当用户输入第一个字符后的一段时间内如果还有字符输入的话,那就暂时不去请求判断用户名是否被占用。
通过闭包保存一个标记来保存 setTimeout 返回的值,每当用户输入时就把 setTimeout clear 掉,然后又创建一个新的 setTimeout,这样就能保证输入字符后的 interval 间隔内如果还有字符输入的话,就不会执行 fn 函数了。
function debounce(fn, interval = 300) {
let timeout = null;
return function () {
clearTimeout(timeout);
timeout = setTimeout(() => {
fn.apply(this, arguments);
}, interval);
};
}垃圾回收
JavaScript 垃圾回收的机制很简单:找出不再使用的变量,然后释放掉其占用的内存,但是这个过程不是时时的,因为其开销比较大,所以垃圾回收器会按照固定的时间间隔周期性的执行。
变量生命周期
不再使用的变量也就是生命周期结束的变量,当然只可能是局部变量,全局变量的生命周期直至浏览器卸载页面才会结束。
局部变量只在函数的执行过程中存在,而在这个过程中会为局部变量在栈或堆上分配相应的空间,以存储它们的值,然后再函数中使用这些变量,直至函数结束(闭包中由于内部函数的原因,外部函数并不能算是结束)。
标记清除 (mark and sweep)
这是 JavaScript 最常见的垃圾回收方式,当变量进入执行环境的时候,比如函数中声明一个变量,垃圾回收器将其标记为“进入环境”,当变量离开环境的时候(函数执行结束)将其标记为“离开环境”。
垃圾回收器会在运行的时候给存储在内存中的所有变量加上标记,然后去掉环境中的变量以及被环境中变量所引用的变量(闭包),在这些完成之后仍存在标记的就是要删除的变量了,因为环境中的变量已经无法访问到这些变量了。
引用计数 (reference counting)
引用计数的策略是跟踪记录每个值被使用的次数,当声明了一个变量并将一个引用类型赋值给该变量的时候这个值的引用次数就加1,如果该变量的值变成了另外一个,则这个值得引用次数减1,当这个值的引用次数变为0的时候,说明没有变量在使用,这个值没法被访问了,因此可以将其占用的空间回收,这样垃圾回收器会在运行的时候清理掉引用次数为0的值占用的空间。
在低版本IE中经常会出现内存泄露,很多时候就是因为其采用引用计数方式进行垃圾回收,这种方式没办法解决循环引用问题。
变量提升
仅针对使用var声明变量的情况,使用let声明不会提升
JavaScript 中,函数及变量的声明都将被提升到函数的最顶部,函数被提升到变量声明之上。
JavaScript 中,变量可以在使用后声明,也就是变量可以先使用再声明。
JavaScript 只有声明的变量会提升,初始化的不会。
严格模式
严格模式通过在脚本或函数的头部添加"use strict";表达式来声明。
严格模式下的限制:
- 不允许使用未声明的变量
- 不允许删除变量或对象
- 不允许删除函数
- 不允许变量重名
- 不允许使用八进制
- 不允许使用转义字符
- 不允许对只读属性赋值
- 不允许对一个使用 getter 方法读取的属性进行赋值
- 不允许删除一个不允许删除的属性
- 变量名不能使用保留关键字
- 由于一些安全原因,在作用域
eval()创建的变量不能被调用 - 禁止
this关键字指向全局对象(因此,使用构造函数时,如果忘了加new,this不再指向全局对象,而是报错)
算法
快速排序
假设要排序的数组是A[0]~A[N-1]
- 设置两个变量
i=0,j=N-1 - 取数组第一个元素作为枢轴量,
k=A[0] - 从
j开始向前搜索,找到第一个小于k的值A[j];从i开始向后搜索,找到第一个大于k的值A[i] - 交换
A[i]与A[j] - 重复3、4,直到
i==j - 对
i的左右部分进行同样的排序操作
时间复杂度
- 最坏情况
O(n²)
每次划分过程产生的两个区间分别包含 n-1 个元素和 1 个元素 - 最好情况
O(nlogn)
每次划分过程产生的两个区间大小都为 n/2 - 平均情况
O(nlogn)
参考资料
http://www.runoob.com
https://juejin.im/entry/582f16fca22b9d006b7afd89
https://juejin.im/entry/58c0379e44d9040068dc952f
https://segmentfault.com/a/1190000004865198
https://segmentfault.com/a/1190000011145364
https://www.cnblogs.com/jianghao233/p/8983176.html
https://www.cnblogs.com/xuehaoyue/p/6639029.html
http://uule.iteye.com/blog/2412003
https://www.cnblogs.com/dolphinX/p/3348468.html
https://www.cnblogs.com/cs_net/articles/1820653.html
https://segmentfault.com/a/1190000011942746
http://www.cnblogs.com/chengzp/p/cssbox.html
https://blog.csdn.net/qq_21794603/article/details/71698943
http://www.ruanyifeng.com/blog/2014/10/event-loop.html
https://www.cnblogs.com/bfgis/p/5460191.html
http://jerryzou.com/posts/cookie-and-web-storage/
https://my.oschina.net/ioslighter/blog/359207
https://www.jianshu.com/p/9535e7924dba
https://segmentfault.com/a/1190000016199807
版权声明:本文为原创文章,版权归 神代綺凜 所有。
本文链接:https://moe.best/gotagota/front-end-developer-interview.html
所有原创文章采用 知识共享署名-非商业性使用 4.0 国际许可协议 进行许可。
您可以自由的转载和修改,但请务必注明文章来源并且不可用于商业目的。
拿走了
我也想做前端,现在读得软件工程,下学期好多算法课,枯了,可是对算法和数学真的很难感兴趣。qwq,感觉还是做前端有意思。自己专业就这个学期是有一门很基础的HTML+CSS选修课,才学了一点,下学期就没了,变成程序算法了。(当然自己也有很努力的在自学,现在在看bootstrap。感觉到后面学校是不会教这方面的内容了。想知道大佬是什么专业的。ヾ(≧∇≦*)ゝ
我双专业,数学与计算科学(数院),信息与计算科学(计软)
突然觉得一键至评论有时候也……挺有用的>﹏<
我博客是 Typecho 驱动,基于 php 的
感觉现在当程序员真难,又要会前端,又要会服务端,还要会各种框架
嘛,就是要你大学的时候多花点时间学各种课外的东西